Bạn đang tìm công cụ để quản lý log trên hàng chục máy chủ khác nhau? Logstash chính là câu trả lời mà các kỹ sư hệ thống và lập trình viên đang tìm kiếm. Đây là một công cụ mạnh mẽ, giúp tập trung, phân tích và trực quan hóa log một cách hiệu quả, biến dữ liệu hỗn loạn thành thông tin chi tiết có giá trị. Trong bài viết này, thuemaychugiare sẽ cùng bạn đi sâu vào từng thành phần cốt lõi, khám phá cách chúng hoạt động và các ứng dụng thực tế.
Logstash là gì?
Logstash là một công cụ mã nguồn mở, server-side (chạy trên máy chủ), chuyên dùng để thu thập, phân tích, làm sạch, và chuyển đổi dữ liệu từ vô số nguồn khác nhau. Logstash là viết tắt của Log + Stash (nơi lưu trữ), và nó chính là thành phần “L” (Logstash) trong bộ ba nổi tiếng ELK Stack là gì (Elasticsearch, Logstash, Kibana).
Khi một hệ thống phần mềm phát triển lớn mạnh, đặc biệt với kiến trúc microservices hay cloud, lượng log sinh ra mỗi giây có thể lên đến hàng nghìn, hàng triệu dòng. Các dòng log này thường nằm rải rác ở nhiều nơi, có định dạng không đồng nhất, gây ra khó khăn lớn trong việc gỡ lỗi, giám sát và phân tích. Đó là lúc Logstash là gì trở thành câu hỏi then chốt.
Vai trò chính của Logstash được gói gọn trong khái niệm ETL (Extract, Transform, Load):
- Extract (Trích xuất): Logstash thu thập dữ liệu từ nhiều nguồn khác nhau (file log, database, message queue, v.v.).
- Transform (Biến đổi): Sau khi trích xuất, Logstash áp dụng các bộ lọc để làm sạch, phân tích, và làm giàu dữ liệu. Đây là bước quan trọng giúp biến dữ liệu thô, không có cấu trúc thành định dạng chuẩn hóa, dễ dàng phân tích hơn.
- Load (Tải): Cuối cùng, Logstash chuyển dữ liệu đã được xử lý đến một đích đến cụ thể, thường là Elasticsearch để lưu trữ và tìm kiếm.
Có thể nói, Logstash chính là “trái tim” của quá trình tiền xử lý dữ liệu trong hệ sinh thái Elastic Stack, đảm bảo dữ liệu đến được Elasticsearch trong tình trạng tốt nhất.

Logstash là gì_
Tại sao Logstash quan trọng?
Nhiều người thắc mắc tại sao nên dùng Logstash khi đã có các công cụ khác. Câu trả lời nằm ở khả năng giải quyết các điểm đau (pain point) cốt lõi trong quản lý dữ liệu log mà các công cụ đơn thuần không làm được:
- Log phân tán và lộn xộn: Các ứng dụng chạy trên nhiều máy chủ, nhiều container tạo ra log ở các định dạng khác nhau. Việc truy cập từng nơi để xem log là bất khả thi. Logstash giúp thu thập tất cả về một mối.
- Dữ liệu thô không có cấu trúc: Hầu hết log ban đầu chỉ là các dòng văn bản đơn thuần. Logstash có thể “parse” (phân tách) các dòng này thành các trường dữ liệu có cấu trúc (ví dụ: IP, mã trạng thái HTTP, user ID), giúp việc tìm kiếm và phân tích trở nên dễ dàng hơn rất nhiều.
- Thiếu thông tin chi tiết: Một dòng log thường chỉ chứa thông tin cơ bản. Logstash có khả năng làm giàu dữ liệu, ví dụ thêm thông tin vị trí địa lý từ địa chỉ IP, thêm thông tin về User-Agent của trình duyệt, hoặc liên kết với các ID giao dịch để có cái nhìn toàn diện hơn.
- Cần phản ứng nhanh với sự cố: Để giám sát hệ thống hiệu quả, việc phân tích log cần diễn ra gần như thời gian thực. Logstash giúp xử lý và đẩy dữ liệu nhanh chóng đến nơi lưu trữ để có thể trực quan hóa ngay lập tức.
- Yêu cầu tích hợp phức tạp: Không phải lúc nào dữ liệu cũng đến từ file log đơn giản. Logstash có khả năng tích hợp với rất nhiều loại nguồn và đích đến khác nhau, từ message queue như Kafka, Redis cho đến database hoặc các API.
Tóm lại, Logstash là chìa khóa để biến “núi” dữ liệu log vô nghĩa thành một nguồn thông tin hữu ích, có cấu trúc, giúp đội ngũ kỹ sư hiểu rõ hơn về hoạt động của hệ thống và giải quyết vấn đề nhanh hơn.

Tại sao Logstash quan trọng
Kiến trúc của Logstash
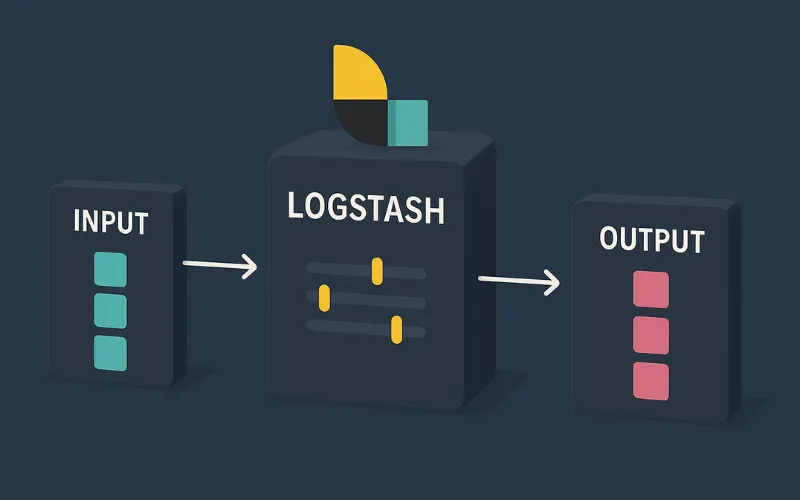
Để hiểu sâu về Logstash là gì và cách nó “biến hình” dữ liệu, chúng ta cần nắm rõ kiến trúc Logstash hay còn gọi là Data Processing Pipeline. Đây là một luồng xử lý tuần tự bao gồm ba giai đoạn chính: Input, Filter và Output.

Kiến trúc Logstash_ Hiểu rõ Data Processing Pipeline
1. Input – Thu thập dữ liệu từ đâu?
Input là giai đoạn đầu tiên của Logstash pipeline, nơi Logstash tiếp nhận dữ liệu từ các nguồn khác nhau. Logstash có rất nhiều plugin input, cho phép nó tương tác với hầu hết các hệ thống phổ biến:
file: Đọc dữ liệu từ các tệp tin log trên hệ thống. Đây là plugin phổ biến nhất khi bạn cần thu thập log từ ứng dụng hoặc server.beats: Nhận dữ liệu từ các “shipper” gọn nhẹ của Elastic là Beats (như Filebeat, Metricbeat, Winlogbeat). Đây là cách triển khai phổ biến và hiệu quả nhất trong các hệ thống phân tán.tcp/udp: Nhận dữ liệu qua các cổng mạng, hữu ích cho các ứng dụng gửi log trực tiếp hoặc các thiết bị mạng.kafka/redis: Đọc dữ liệu từ các hàng đợi tin nhắn (message queue) để tăng tính ổn định và khả năng chịu lỗi.stdin: Đọc dữ liệu từ dòng lệnh, thường dùng để kiểm thử hoặc debug.syslog: Thu thập log từ các hệ thống sử dụng giao thức syslog.
2. Filter – Xử lý và Biến đổi dữ liệu thế nào?
Giai đoạn Filter là linh hồn của Logstash, nơi dữ liệu thô được làm sạch, phân tích, và làm giàu. Logstash cung cấp một kho plugin filter khổng lồ, cho phép bạn thực hiện mọi thao tác cần thiết:
grok: Plugin cực kỳ mạnh mẽ dùng để parse (phân tách) các dòng log không có cấu trúc thành các trường dữ liệu có tên. Ví dụ, nó có thể bóc tách IP, user-agent, mã trạng thái từ một dòng log Apache. Đây là một kỹ năng quan trọng khi bạn làm việc với Logstash.mutate: Cho phép bạn thực hiện các thao tác cơ bản trên các trường dữ liệu: đổi tên, thêm, xóa, sửa đổi giá trị, nối chuỗi, chuyển đổi kiểu dữ liệu (từ chuỗi sang số).date: Parse các chuỗi thời gian thành định dạng chuẩn ISO 8601, cực kỳ quan trọng để đảm bảo việc sắp xếp và tìm kiếm dữ liệu theo thời gian chính xác.geoip: Dùng địa chỉ IP để thêm các thông tin vị trí địa lý (quốc gia, thành phố, vĩ độ/kinh độ) vào log, giúp bạn trực quan hóa trên bản đồ.useragent: Phân tích chuỗi User-Agent của trình duyệt web để bóc tách thông tin về hệ điều hành, trình duyệt, thiết bị của người dùng.json: Parse các chuỗi JSON thành các đối tượng JSON, rất hữu ích khi log của bạn đã ở định dạng JSON.
3. Output – Dữ liệu sẽ đi đâu?
Sau khi dữ liệu đã được thu thập và xử lý, giai đoạn Output sẽ đẩy chúng đến đích cuối cùng. Logstash cũng hỗ trợ rất nhiều plugin output:
-
elasticsearch: Đây là output phổ biến nhất, nơi dữ liệu được đẩy vào Elasticsearch để lưu trữ, lập chỉ mục và sẵn sàng cho việc tìm kiếm/trực quan hóa bằng Kibana.file: Ghi dữ liệu đã xử lý vào một tệp tin khác, hữu ích cho việc lưu trữ lâu dài hoặc chuyển tiếp đến các hệ thống khác.stdout: In dữ liệu ra console (màn hình), thường dùng để debug cấu hình Logstash.kafka/redis: Đẩy dữ liệu vào các message queue khác để xử lý tiếp bởi các dịch vụ khác.s3: Lưu trữ dữ liệu vào Amazon S3.
Logstash hoạt động như thế nào?
Logstash hoạt động như thế nào
Để hiểu rõ Logstash hoạt động như thế nào trong một hệ thống thực tế, hãy xem xét ví dụ về việc xử lý log truy cập từ máy chủ Nginx.
- Phát sinh Log: Một khách hàng truy cập vào website của bạn được phục vụ bởi máy chủ Nginx. Nginx ghi lại một dòng log vào file
/var/log/nginx/access.log, ví dụ:
192.168.1.10 - - [10/Oct/2023:14:30:00 +0700] "GET /api/users/123 HTTP/1.1" 200 125 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" - Thu thập bởi Filebeat: Trên máy chủ Nginx, một agent gọn nhẹ như Filebeat được cài đặt. Filebeat liên tục giám sát file
/var/log/nginx/access.log. Ngay khi dòng log mới xuất hiện, Filebeat đọc nó và gửi đến Logstash. - Logstash Input: Logstash nhận dòng log từ Filebeat thông qua plugin
beatsinput đã được cấu hình. - Logstash Filter – Parse với Grok: Logstash áp dụng bộ lọc
grok. Với một pattern được định nghĩa trước (ví dụ:%{IPORHOST:clientip} %{HTTPUSERAGENT:user_agent_raw}…), Logstash sẽ phân tách dòng log Nginx thành các trường có cấu trúc như:clientip: “192.168.1.10”timestamp: “10/Oct/2023:14:30:00 +0700”request_method: “GET”request_path: “/api/users/123”response_code: 200bytes_sent: 125user_agent_raw: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36”
- Logstash Filter – Làm giàu với GeoIP và User Agent:
- Logstash áp dụng bộ lọc
geoiplên trườngclientip, thêm vào các trường mới nhưclient_geo.country_name,client_geo.city_name. - Logstash áp dụng bộ lọc
useragentlên trườnguser_agent_raw, thêm vào các trường nhưuser_agent.os,user_agent.name.
- Logstash áp dụng bộ lọc
- Logstash Filter – Chuẩn hóa thời gian: Bộ lọc
datesẽ chuyển đổi chuỗitimestampthành định dạng datetime chuẩn, thường là UTC. - Logstash Output: Cuối cùng, Logstash đẩy đối tượng JSON đã xử lý và làm giàu này vào Elasticsearch thông qua plugin
elasticsearchoutput.
Sau quá trình này, dữ liệu log Nginx thô đã được “biến hình” thành một đối tượng JSON có cấu trúc rõ ràng, đầy đủ thông tin, sẵn sàng cho việc tìm kiếm trên Elasticsearch và trực quan hóa trên Kibana. Đây là một ví dụ mạnh mẽ về Logstash grok filter ví dụ và cách Logstash thực sự làm sạch và làm giàu dữ liệu.
Cài đặt và Cấu hình Logstash cơ bản
Để bắt đầu trải nghiệm Logstash là gì, bạn có thể cài đặt và cấu hình Logstash một cách cơ bản. Đây là một hướng dẫn nhanh cho môi trường Linux hoặc Docker.
Cài đặt Logstash trên Linux (Ubuntu/Debian)
- Cài đặt Java (JRE): Logstash yêu cầu Java Virtual Machine (JVM).
sudo apt update && sudo apt install default-jre - Thêm Elastic PGP key:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elastic.gpg - Thêm repository của Elastic:
echo "deb [signed-by=/usr/share/keyrings/elastic.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.list - Cài đặt Logstash:
sudo apt update && sudo apt install logstash
Cài đặt Logstash với Docker
Cách nhanh và phổ biến nhất để thử nghiệm Logstash là sử dụng Docker.
- Yêu cầu: Máy tính của bạn đã cài đặt Docker và Docker Compose.
- Tạo file
docker-compose.yml:version: '3.7' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0 container_name: elasticsearch environment: - discovery.type=single-node - xpack.security.enabled=false ports: - "9200:9200" networks: - elk logstash: image: docker.elastic.co/logstash/logstash:8.9.0 container_name: logstash volumes: - ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml - ./logstash/pipeline:/usr/share/logstash/pipeline ports: - "5044:5044" environment: LS_JAVA_OPTS: "-Xmx256m -Xms256m" networks: - elk depends_on: - elasticsearch kibana: image: docker.elastic.co/kibana/kibana:8.9.0 container_name: kibana ports: - "5601:5601" depends_on: - elasticsearch networks: - elk networks: elk: driver: bridgeLưu ý: Phiên bản
8.9.0là ví dụ. Cần tạo thư mụclogstash/configvàlogstash/pipeline. - Tạo file cấu hình Logstash (
logstash/pipeline/simple.conf):input { stdin {} } filter { mutate { add_field => { "source_app" => "console_test" } } } output { stdout { codec => rubydebug } } - Khởi chạy: Mở terminal và chạy lệnh:
docker-compose up -d
Đây chỉ là hướng dẫn sử dụng Logstash cơ bản. Trong môi trường sản phẩm, cấu hình sẽ phức tạp hơn rất nhiều.
Tối ưu hiệu năng và Khả năng chịu lỗi cho Logstash
Một trong những bận tâm lớn của kỹ sư khi triển khai Logstash là vấn đề hiệu năng và khả năng chịu lỗi. Logstash có tốn tài nguyên không là câu hỏi thường gặp. Do Logstash chạy trên Java Virtual Machine (JVM), nó có thể tiêu tốn khá nhiều CPU và RAM, đặc biệt khi xử lý lượng dữ liệu lớn.
Dưới đây là một số cách để tối ưu hiệu năng Logstash và tăng khả năng chịu lỗi:
- Tối ưu JVM Heap Size: Điều chỉnh biến môi trường
LS_JAVA_OPTS(ví dụ:-Xmx1g -Xms1g) để cấp phát lượng RAM phù hợp. - Điều chỉnh Batch Size và Workers: Điều chỉnh
pipeline.batch.sizevàpipeline.workerstrong file cấu hình để tối ưu throughput và tận dụng CPU. - Sử dụng Persistent Queues: Tính năng này giúp Logstash lưu trữ tạm thời dữ liệu ra đĩa, đảm bảo fault tolerance logstash và không mất dữ liệu khi có sự cố.
- Sử dụng Message Queues (Kafka/Redis): Đặt một message queue như Apache Kafka hoặc Redis giữa shipper và Logstash để cân bằng tải và tạo vùng đệm.
- Giảm thiểu các filter phức tạp: Tối ưu các pattern
grokhoặc xem xét xử lý parse log ở giai đoạn trước nếu có thể. - Triển khai trên hạ tầng phù hợp: Để Logstash hoạt động ổn định, việc có một hạ tầng máy chủ đủ mạnh mẽ là cực kỳ quan trọng. thuemaychugiare cung cấp các giải pháp máy chủ vật lý và ảo với cấu hình cao, đáp ứng tốt nhu cầu triển khai Logstash.
Logstash trong Elastic Stack: Khi nào nên dùng Logstash?
Logstash không phải là công cụ duy nhất để xử lý log trong Elastic Stack. Đặc biệt, sự xuất hiện của Beats thường gây nhầm lẫn về vai trò của từng công cụ. Vậy khi nào nên dùng Logstash?
Logstash vs Filebeat: Sự khác biệt và lựa chọn
Đây là một trong những câu hỏi phổ biến nhất. Dưới đây là bảng so sánh ngắn gọn:
| Tiêu chí | Filebeat | Logstash |
|---|---|---|
| Bản chất | Agent thu thập (data shipper) | Công cụ xử lý dữ liệu (data processor/ETL) |
| Kích thước/Tài nguyên | Rất nhẹ, tiêu tốn ít tài nguyên | Nặng hơn (chạy JVM), tiêu tốn nhiều tài nguyên hơn |
| Vị trí | Cài đặt trên máy chủ nguồn (client-side) | Cài đặt trên máy chủ tập trung (server-side) |
| Chức năng chính | Đọc file, thu thập dữ liệu và gửi đi | Xử lý phức tạp: parse, filter, enrich |
| Khả năng xử lý | Hạn chế, chỉ làm những thao tác đơn giản | Mạnh mẽ, nhiều plugin filter phức tạp |
Thực tế, mô hình phổ biến nhất là sử dụng Filebeat gửi dữ liệu đến Logstash, sau đó Logstash xử lý và gửi đến Elasticsearch. Filebeat đảm bảo thu thập hiệu quả trên client, Logstash đảm nhiệm xử lý mạnh mẽ ở server.
Logstash vs Fluentd
Fluentd là một đối thủ cạnh tranh đáng gờm của Logstash. Lựa chọn giữa hai công cụ thường phụ thuộc vào hệ sinh thái hiện có và yêu cầu cụ thể về hiệu suất/tài nguyên. Nếu bạn đã và đang sử dụng Elastic Stack, Logstash là lựa chọn tự nhiên.
Câu hỏi thường gặp về Logstash (FAQ)
Logstash có cần JVM không?
Có. Logstash được viết bằng Ruby và chạy trên Java Virtual Machine (JVM). Do đó, bạn cần cài đặt Java (JRE/JDK) trên máy chủ để Logstash có thể hoạt động.
Logstash có thể gửi dữ liệu đến đâu ngoài Elasticsearch?
Logstash rất linh hoạt với nhiều plugin output khác nhau. Ngoài Elasticsearch, Logstash có thể gửi dữ liệu đến File, Apache Kafka, Redis, S3, MongoDB, PostgreSQL, và nhiều hơn nữa.
Logstash có phiên bản miễn phí không?
Có. Logstash là một dự án mã nguồn mở và hoàn toàn miễn phí để sử dụng (theo giấy phép Elastic License).
Lời kết
Chúng ta đã cùng nhau tìm hiểu sâu về Logstash là gì, từ định nghĩa cơ bản, kiến trúc pipeline, cách Logstash hoạt động, cho đến các phương pháp tối ưu hiệu năng và so sánh với các công cụ khác. Có thể nói, Logstash là một thành phần không thể thiếu trong bất kỳ giải pháp quản lý log tập trung nào, giúp biến những dòng log tưởng chừng vô nghĩa thành nguồn thông tin phong phú và có giá trị.
Nắm vững Logstash giúp các kỹ sư có khả năng xử lý và phân tích dữ liệu log một cách chuyên nghiệp, từ đó nâng cao khả năng giám sát, gỡ lỗi và đảm bảo an toàn cho hệ thống. Để triển khai một hệ thống Logstash ổn định và hiệu quả, đặc biệt là với khối lượng dữ liệu lớn, việc có một hạ tầng máy chủ mạnh mẽ và đáng tin cậy là yếu tố then chốt.
Để lại một bình luận