Trong thế giới số, dữ liệu được ví như vàng. Nhưng nếu bạn có một kho vàng khổng lồ mà không thể tìm thấy thứ mình cần một cách nhanh chóng, thì kho báu đó cũng trở nên vô giá trị. Bài viết này sẽ là kim chỉ nam toàn diện giúp bạn giải mã Elasticsearch là gì, khám phá “bí mật” giúp nó tìm kiếm nhanh như chớp qua cơ chế Inverted Index, phân tích rõ ràng ưu và nhược điểm, đặt nó lên bàn cân so với cơ sở dữ liệu quan hệ (RDBMS), và xem qua những ứng dụng thực tế ấn tượng.
Elasticsearch là gì?
Elasticsearch là một công cụ tìm kiếm và phân tích phân tán, mã nguồn mở, được xây dựng dựa trên thư viện tìm kiếm cực kỳ mạnh mẽ có tên là Apache Lucene.
Nhiều người thường nhầm lẫn và gọi Elasticsearch đơn giản là một cơ sở dữ liệu NoSQL. Điều này không sai, vì Elasticsearch thực sự lưu trữ dữ liệu dưới dạng các tài liệu JSON document linh hoạt. Tuy nhiên, việc chỉ xem Elasticsearch như một database sẽ bỏ qua sức mạnh cốt lõi và mục đích ra đời của nó.
Hãy nghĩ về Elasticsearch theo thứ tự ưu tiên sau:
- Là một công cụ tìm kiếm (Search Engine): Chức năng chính và mạnh mẽ nhất của Elasticsearch là khả năng thực hiện full-text search (tìm kiếm toàn văn) và các truy vấn phức tạp trên một lượng lớn dữ liệu với tốc độ gần như thời gian thực.
- Là một công cụ phân tích (Analytics Engine): Elasticsearch cho phép bạn thực hiện các truy vấn tổng hợp (aggregations) mạnh mẽ để phân tích, thống kê và trực quan hóa dữ liệu.
- Là một cơ sở dữ liệu NoSQL phân tán: Nó lưu trữ, quản lý và truy xuất dữ liệu một cách hiệu quả trên nhiều máy chủ.
Elasticsearch chính là thành phần trung tâm, là “trái tim” của ELK Stack là gì (nay là Elastic Stack), một bộ công cụ hoàn chỉnh cho việc quản lý log và phân tích dữ liệu, bao gồm Elasticsearch, Logstash, Kibana và Beats.

Elasticsearch là gì
Tại sao Elasticsearch ra đời?
Để hiểu giá trị của Elasticsearch, hãy nhìn vào những vấn đề mà các lập trình viên thường xuyên đối mặt với cơ sở dữ liệu quan hệ (SQL) truyền thống.
Giả sử bạn có một website thương mại điện tử với hàng triệu sản phẩm, và bạn muốn xây dựng tính năng tìm kiếm. Nếu dùng SQL, bạn có thể sẽ nghĩ đến câu lệnh:
SELECT * FROM products WHERE description LIKE '%giày thể thao nam màu trắng%';Câu lệnh này có hai vấn đề nghiêm trọng:
- Cực kỳ chậm (Slow): Toán tử
LIKE '%...%'không thể sử dụng index hiệu quả. Khi bảng sản phẩm của bạn lớn lên, truy vấn này sẽ quét toàn bộ bảng (full table scan), khiến thời gian phản hồi tăng lên theo cấp số nhân. - Không thông minh (Not Relevant): Kết quả trả về không có sự xếp hạng. Một sản phẩm chỉ có từ “giày” sẽ có độ ưu tiên ngang với sản phẩm có đầy đủ cụm từ “giày thể thao nam màu trắng“. Nó không hiểu được sai chính tả, từ đồng nghĩa, hay mức độ liên quan của kết quả.
Đây chính là lúc Elasticsearch tỏa sáng. Nó được thiết kế từ đầu để giải quyết bài toán full-text search một cách hiệu quả. Tương tự, với bài toán phân tích log, việc thực hiện các truy vấn tổng hợp phức tạp trên hàng tỷ dòng log bằng SQL gần như là bất khả thi trong thời gian thực. Elasticsearch cung cấp một giải pháp mạnh mẽ và có khả năng mở rộng để giải quyết những vấn đề này.
Tại sao Elasticsearch ra đời
Ưu – Nhược điểm của Elasticsearch
Ưu điểm
- Tốc độ cực nhanh: Nhờ kiến trúc Inverted Index, Elasticsearch có thể trả về kết quả tìm kiếm và phân tích trên hàng petabyte dữ liệu chỉ trong mili giây.
- Khả năng mở rộng tuyệt vời: Được thiết kế theo kiến trúc phân tán, bạn có thể dễ dàng thêm các node mới vào cluster để tăng khả năng lưu trữ và xử lý (mở rộng theo chiều ngang).
- Tìm kiếm toàn văn mạnh mẽ (Full-Text Search): Hỗ trợ các truy vấn phức tạp, phân tích ngôn ngữ, xếp hạng mức độ liên quan, tự động sửa lỗi, gợi ý,…
- Linh hoạt (Schema-less): Bạn có thể đưa dữ liệu JSON vào mà không cần định nghĩa cấu trúc (schema) trước, giúp việc phát triển trở nên nhanh chóng.Hệ sinh thái mạnh mẽ: Là một phần của Elastic Stack (ELK), nó có sự hỗ trợ của Kibana (trực quan hóa), Logstash và Beats (thu thập dữ liệu), tạo thành một giải pháp end-to-end hoàn chỉnh.
Nhược điểm
- Không phải là giải pháp cho transactional data: Elasticsearch không hỗ trợ các giao dịch ACID phức tạp như cơ sở dữ liệu quan hệ. Nó không phù hợp cho các hệ thống yêu cầu tính toàn vẹn dữ liệu tuyệt đối như hệ thống ngân hàng.
- Độ dốc học tập (Steep Learning Curve): Việc vận hành, tối ưu và quản lý một cluster Elasticsearch trong môi trường production đòi hỏi kiến thức chuyên sâu về các khái niệm như sharding, replication, và cluster management.
- Ngốn tài nguyên: Elasticsearch, đặc biệt là Java Virtual Machine (JVM) mà nó chạy trên, yêu cầu một lượng lớn RAM để có thể hoạt động hiệu quả.
“Near” Real-Time, không phải Real-Time: Có một độ trễ nhỏ (thường là 1 giây) từ lúc dữ liệu được đưa vào cho đến khi nó sẵn sàng để tìm kiếm.
So sánh Chi tiết: Elasticsearch vs. RDBMS (Cơ sở dữ liệu Quan hệ)
Elasticsearch không thay thế được RDBMS (như MySQL, PostgreSQL). Chúng được thiết kế để giải quyết các bài toán khác nhau và thường bổ trợ cho nhau.
| Tiêu chí | Elasticsearch | RDBMS (MySQL, PostgreSQL, …) |
|---|---|---|
| Mục đích chính | Tìm kiếm, phân tích log, và các truy vấn phân tích phức tạp. | Quản lý dữ liệu có cấu trúc, giao dịch (transactions), đảm bảo tính toàn vẹn dữ liệu. |
| Cấu trúc dữ liệu | JSON Documents (linh hoạt, không bắt buộc schema – schema-less). | Bảng (Tables) với các hàng (rows) và cột (columns) có schema nghiêm ngặt. |
| Ngôn ngữ truy vấn | RESTful API với Query DSL (dạng JSON). | SQL (Structured Query Language). |
| Giao dịch (ACID) | Không hỗ trợ các giao dịch đa tài liệu phức tạp. | Hỗ trợ đầy đủ (Atomicity, Consistency, Isolation, Durability). |
| Mối quan hệ (Joins) | Hỗ trợ hạn chế (nested objects, parent-child). Join phức tạp rất tốn kém. | Rất mạnh trong việc thực hiện các phép JOIN phức tạp giữa các bảng. |
| Khả năng mở rộng | Mở rộng theo chiều ngang (Horizontal scaling) rất dễ dàng bằng cách thêm node. | Mở rộng theo chiều dọc (Vertical scaling) là chủ yếu (nâng cấp phần cứng). Mở rộng ngang phức tạp hơn. |
Kiến trúc phổ biến: Sử dụng RDBMS làm nguồn dữ liệu chính (source of truth) cho các hoạt động ghi và giao dịch, sau đó đồng bộ dữ liệu sang Elasticsearch để phục vụ cho các tác vụ tìm kiếm và phân tích tốc độ cao.
Các khái niệm kiến trúc cốt lõi của Elasticsearch
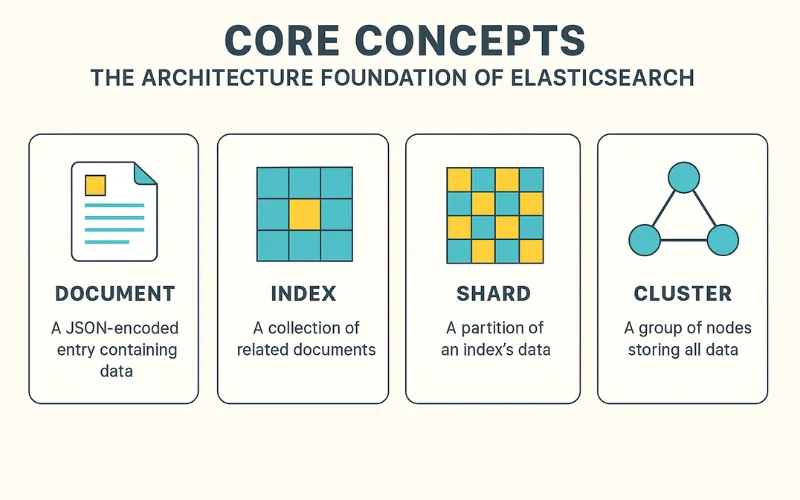
Để làm việc hiệu quả với Elasticsearch, việc nắm vững các khái niệm kiến trúc cốt lõi là điều bắt buộc. Đây là những thuật ngữ bạn sẽ gặp hàng ngày.
Các khái niệm cốt lõi
Document & Index (Tài liệu & Chỉ mục)
- Document: Là đơn vị thông tin cơ bản được lưu trữ trong Elasticsearch, được biểu diễn dưới dạng một đối tượng JSON. Nếu so sánh với SQL, một
Documenttương đương với mộthàng(row) trong bảng. - Index: Là một tập hợp các
Documentcó cấu trúc tương tự nhau. MộtIndextương đương với mộtbảng(table) trong SQL. Bạn sẽ có một index cho sản phẩm, một index cho người dùng, một index cho log,…
Node & Cluster (Nút & Cụm)
- Node: Là một thực thể máy chủ (server) duy nhất đang chạy một phiên bản của Elasticsearch. Một
Nodetham gia vào việc lưu trữ dữ liệu và xử lý các truy vấn. - Cluster: Là một tập hợp gồm một hoặc nhiều
Nodelàm việc cùng nhau. MộtClustercung cấp khả năng lưu trữ và xử lý truy vấn trên toàn bộ dữ liệu của bạn. Việc có nhiều node trong một cluster giúp đảm bảo tính chịu lỗi và khả năng mở rộng.
Để vận hành một cluster Elasticsearch ổn định, đặc biệt trong môi trường production, bạn cần các máy chủ có cấu hình mạnh mẽ và kết nối mạng tốt. Đây là lúc các dịch vụ của thuemaychugiare có thể cung cấp hạ tầng vững chắc cho hệ thống của bạn.
Shard & Replica (Mảnh & Bản sao)
- Shard (Mảnh): Khi một
Indexcó quá nhiều dữ liệu, Elasticsearch cho phép bạn chia nhỏ index đó thành nhiều phần gọi làShard. Mỗi shard là một “chỉ mục con” độc lập và đầy đủ chức năng, có thể được lưu trữ trên bất kỳ node nào trong cluster. Việc chia shard giúp song song hóa các tác vụ, từ đó tăng hiệu năng và cho phép lưu trữ nhiều dữ liệu hơn khả năng của một node duy nhất. - Replica (Bản sao): Là một bản sao của một
Shard.Replicađược tạo ra với hai mục đích chính:- Tăng tính sẵn sàng cao (High Availability): Nếu một node chứa shard chính (primary shard) bị lỗi, replica shard trên một node khác sẽ được nâng lên làm primary, đảm bảo hệ thống vẫn hoạt động.
- Tăng hiệu năng đọc (Read Performance): Các truy vấn tìm kiếm có thể được thực hiện trên cả primary shard và replica shard, giúp phân tán tải.
Hiểu rõ kiến trúc elasticsearch với các khái niệm node, cluster, index, document, shard, replica là nền tảng để thiết kế và vận hành một hệ thống Elasticsearch hiệu quả và bền vững.
Elasticsearch hoạt động như thế nào?
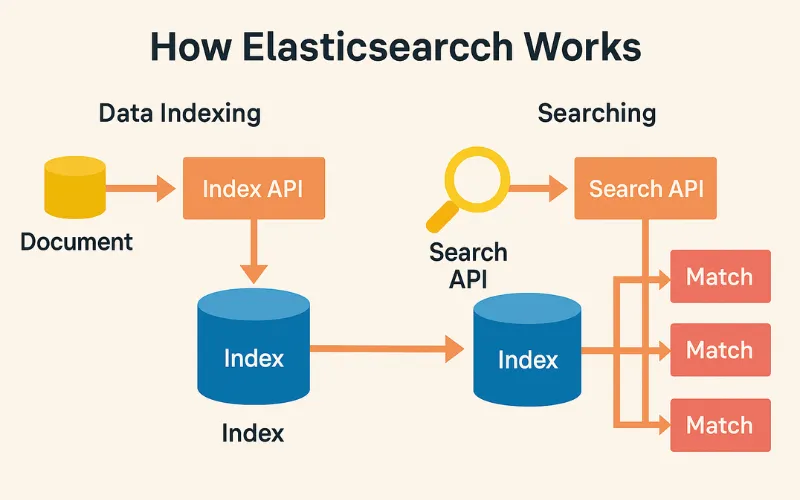
Câu hỏi lớn nhất mà mọi người đặt ra là: Tại sao Elasticsearch tìm kiếm nhanh đến vậy? Câu trả lời nằm ở một cấu trúc dữ liệu cốt lõi được gọi là Inverted Index (Chỉ mục ngược).
Elasticsearch hoạt động như thế nào_
Inverted Index – “Cuốn từ điển” của dữ liệu
Hãy tưởng tượng bạn muốn tìm một từ khóa trong một cuốn sách dày 1000 trang. Thay vì đọc từ trang 1 đến trang 1000, bạn sẽ làm gì? Bạn sẽ lật ra phần mục lục ở cuối sách, tìm từ khóa đó, và xem nó xuất hiện ở những trang nào.
Inverted Index hoạt động chính xác theo cách đó. Khi bạn đưa một Document vào Elasticsearch, quá trình Indexing sẽ diễn ra:
- Phân tích (Analysis): Elasticsearch lấy nội dung của các trường văn bản.
- Token hóa (Tokenization): Nó chia nhỏ nội dung thành các từ riêng lẻ, gọi là “token” (ví dụ: “giày thể thao nam” -> “giày”, “thể”, “thao”, “nam”).
- Xây dựng Inverted Index: Elasticsearch tạo ra một cấu trúc dữ liệu trông giống như một cuốn từ điển. Nó liệt kê tất cả các token duy nhất và với mỗi token, nó ghi lại danh sách các document chứa token đó.
Ví dụ:
giày: [Document 1, Document 5, Document 23]thể: [Document 1, Document 8]thao: [Document 1, Document 8]nam: [Document 1, Document 23, Document 40]
Khi bạn thực hiện một truy vấn tìm kiếm cho “giày nam”, Elasticsearch sẽ:
- Tìm “giày” trong Inverted Index -> Lấy danh sách [Doc 1, Doc 5, Doc 23].
- Tìm “nam” trong Inverted Index -> Lấy danh sách [Doc 1, Doc 23, Doc 40].
- Tìm giao điểm của hai danh sách -> [Doc 1, Doc 23].
Toàn bộ quá trình này diễn ra cực kỳ nhanh vì nó chỉ làm việc trên các danh sách đã được sắp xếp sẵn, thay vì phải quét qua nội dung của từng document. Đây chính là bí mật giải thích Elasticsearch hoạt động như thế nào và tại sao nó có thể trả về kết quả trong mili giây trên hàng tỷ document.
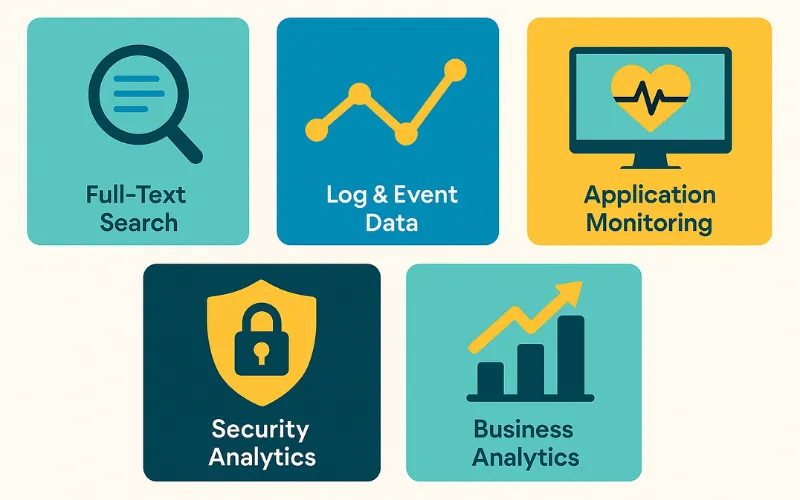
5 Ứng dụng thực tế của Elasticsearch
Với khả năng tìm kiếm và phân tích mạnh mẽ, ứng dụng của Elasticsearch vô cùng đa dạng và có mặt trong rất nhiều hệ thống lớn mà bạn có thể đang sử dụng hàng ngày.
5 Ứng dụng của Elasticsearch
1. Tìm kiếm cho Website và Ứng dụng (E-commerce, Báo chí)
Đây là ứng dụng phổ biến nhất. Các trang thương mại điện tử như Tiki, Shopee hay các trang tin tức đều sử dụng các công cụ tìm kiếm tương tự Elasticsearch để cung cấp tính năng tìm kiếm sản phẩm/bài viết nhanh, chính xác, với các gợi ý, tự động sửa lỗi và xếp hạng kết quả theo mức độ liên quan.
2. Quản lý và Phân tích Log (Centralized Logging)
Với vai trò là trái tim của ELK Stack, Elasticsearch là nơi lưu trữ và lập chỉ mục toàn bộ log từ hệ thống. Các kỹ sư DevOps có thể sử dụng Kibana để tìm kiếm, lọc và tạo dashboard từ hàng terabyte log để giám sát hệ thống, phát hiện sự cố và phân tích các hành vi bất thường.
3. Giám sát hiệu năng ứng dụng (APM – Application Performance Monitoring)
Elastic APM sử dụng Elasticsearch để lưu trữ và phân tích các dữ liệu về hiệu năng (metrics, traces, logs) từ các ứng dụng. Điều này giúp các lập trình viên xác định các “nút thắt cổ chai”, tối ưu hóa các câu lệnh truy vấn chậm và theo dõi sức khỏe của ứng dụng trong thời gian thực.
4. Phân tích Dữ liệu Kinh doanh (Business Intelligence)
Doanh nghiệp có thể đẩy dữ liệu kinh doanh (doanh thu, đơn hàng, hành vi người dùng) vào Elasticsearch. Sau đó, họ có thể sử dụng khả năng tổng hợp (aggregation) mạnh mẽ của Elasticsearch để xây dựng các dashboard phân tích, theo dõi các chỉ số KPI và đưa ra quyết định kinh doanh dựa trên dữ liệu.
5. Phân tích Dữ liệu không gian địa lý (Geospatial Analysis)
Elasticsearch hỗ trợ rất tốt các kiểu dữ liệu và truy vấn không gian địa lý. Các ứng dụng như ứng dụng đặt xe, tìm cửa hàng gần nhất, hay phân tích sự phân bố của các sự kiện trên bản đồ đều có thể được xây dựng hiệu quả trên Elasticsearch.
Hướng dẫn cài đặt và tương tác cơ bản với Elasticsearch
Cách dễ nhất để bắt đầu với Elasticsearch là sử dụng Docker.
Cài đặt nhanh với Docker
- Yêu cầu: Máy tính đã cài đặt Docker và Docker Compose.
- Tạo file
docker-compose.yml:version: '3.7' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0 container_name: elasticsearch environment: - discovery.type=single-node - xpack.security.enabled=false - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ports: - "9200:9200" - "9300:9300"Lưu ý: Phiên bản
8.9.0là ví dụ.xpack.security.enabled=falselà để đơn giản hóa, không nên dùng trong môi trường production. - Khởi chạy: Mở terminal và chạy lệnh:
docker-compose up -d - Kiểm tra: Mở trình duyệt và truy cập
http://localhost:9200. Bạn sẽ thấy một thông báo JSON từ Elasticsearch.
Giao tiếp qua RESTful API – Các lệnh cơ bản
Mọi tương tác với Elasticsearch đều được thực hiện qua RESTful API. Bạn có thể dùng curl hoặc các công cụ như Postman, Kibana Dev Tools.
- Tạo một document:
curl -X POST "localhost:9200/products/_doc/1" -H 'Content-Type: application/json' -d'{"name": "Giày chạy bộ ABC", "price": 1200000, "brand": "BrandX"}' - Lấy một document:
curl -X GET "localhost:9200/products/_doc/1" - Tìm kiếm document:
curl -X GET "localhost:9200/products/_search?q=name:giày"
So sánh Elasticsearch với các công nghệ khác
Elasticsearch vs Solr
Cả hai đều là những công cụ tìm kiếm mã nguồn mở hàng đầu, xây dựng trên Apache Lucene.
- Điểm chung: Cực kỳ mạnh mẽ trong full-text search.
- Khác biệt: Elasticsearch thường được coi là dễ cài đặt và mở rộng hơn, có hệ sinh thái (ELK Stack) mạnh hơn cho việc phân tích log. Solr có cộng đồng lâu đời và mạnh mẽ hơn trong các ứng dụng tìm kiếm truyền thống.
Elasticsearch có thay thế được Database SQL không?
Không hoàn toàn. Chúng được thiết kế để giải quyết các vấn đề khác nhau và thường bổ trợ cho nhau.
- SQL (như MySQL, PostgreSQL): Rất mạnh trong các giao dịch (transactions), đảm bảo tính nhất quán dữ liệu (ACID), và các mối quan hệ phức tạp (joins).
- Elasticsearch: Rất mạnh trong tìm kiếm văn bản và phân tích dữ liệu lớn. Nó không hỗ trợ transactions theo cách của SQL.
Một kiến trúc phổ biến là sử dụng một database SQL làm nguồn dữ liệu chính (source of truth) và đồng bộ dữ liệu sang Elasticsearch để phục vụ cho các tác vụ tìm kiếm và phân tích.
Câu hỏi thường gặp về Elasticsearch (FAQ)
Elasticsearch có miễn phí không?
Có. Các tính năng cốt lõi của Elasticsearch là mã nguồn mở và miễn phí sử dụng (Bản quyền Basic). Tuy nhiên, Elastic cung cấp các gói trả phí với các tính năng nâng cao như machine learning, alerting, bảo mật chi tiết và hỗ trợ kỹ thuật chuyên nghiệp.
Dữ liệu trong Elasticsearch được lưu ở đâu?
Dữ liệu được lưu trên đĩa của các node trong cluster, dưới dạng các file của thư viện Lucene.
Làm thế nào để trực quan hóa dữ liệu từ Elasticsearch?
Kibana là công cụ chính thức và mạnh mẽ nhất trong Elastic Stack để trực quan hóa dữ liệu. Nó cho phép bạn tạo ra các biểu đồ, bảng, bản đồ và dashboard tương tác từ dữ liệu được lưu trong Elasticsearch.
Lời kết
Qua bài viết này, hy vọng bạn đã có một cái nhìn toàn diện về Elasticsearch là gì, từ kiến trúc, cơ chế hoạt động cho đến những ứng dụng thực tiễn. Elasticsearch không chỉ là một công cụ, mà là một nền tảng mạnh mẽ, mở ra những khả năng vô tận trong việc khai thác giá trị từ dữ liệu. Dù bạn đang xây dựng tính năng tìm kiếm cho một trang web, phân tích hàng tỷ dòng log, hay theo dõi hiệu năng hệ thống, Elasticsearch đều là một lựa chọn hàng đầu.
Để khai thác tối đa sức mạnh của một hệ thống phân tán như Elasticsearch, việc có một hạ tầng máy chủ vững chắc, hiệu năng cao và có khả năng mở rộng là điều kiện tiên quyết. Nếu bạn đang tìm kiếm một giải pháp hạ tầng đáng tin cậy. Hãy để thuemaychugiare giải thích cho bạn thêm các vấn đề chưa biết cho bạn!
Để lại một bình luận