Bạn đang vật lộn với việc quản lý log trên hàng chục máy chủ khác nhau? ELK Stack chính là câu trả lời mà các kỹ sư hệ thống và lập trình viên đang tìm kiếm. Đây là bộ công cụ mã nguồn mở hàng đầu, giúp tập trung, phân tích và trực quan hóa log một cách hiệu quả, biến dữ liệu hỗn loạn thành thông tin chi tiết có giá trị. Trong bài viết này, thuemaychugiare sẽ cùng bạn đi sâu vào từng thành phần cốt lõi, khám phá cách chúng hoạt động và các ứng dụng thực tế.
ELK Stack là gì?
Nếu bạn là một Lập trình viên hay Kỹ sư hệ thống, bạn chắc hẳn đã từng trải qua cảm giác bất lực khi phải dò tìm lỗi trong một hệ thống microservices phức tạp. Log, dấu vết quan trọng nhất, lại nằm rải rác trên hàng chục, thậm chí hàng trăm máy chủ khác nhau. Việc truy cập vào từng máy chủ để tìm kiếm thủ công không khác gì mò kim đáy bể, tốn thời gian và cực kỳ kém hiệu quả. Đây chính là “cơn ác mộng” mà ELK Stack ra đời để giải quyết.
Hiểu một cách đơn giản, ELK Stack là một bộ công cụ mã nguồn mở mạnh mẽ, được thiết kế chuyên biệt cho việc quản lý log tập trung (centralized logging). ELK không phải là một sản phẩm đơn lẻ, mà là sự kết hợp của ba dự án cốt lõi:
- Elasticsearch: Lưu trữ và tìm kiếm log.
- Logstash: Thu thập và xử lý log.
- Kibana: Trực quan hóa và phân tích log.
Ngày nay, bộ công cụ này đã được mở rộng và có tên gọi chính thức hơn là Elastic Stack, với sự bổ sung của một thành phần quan trọng là Beats. Tại thuemaychugiare, chúng tôi nhận thấy rất nhiều khách hàng triển khai giải pháp này trên các hệ thống máy chủ hiệu năng cao để đảm bảo khả năng xử lý lượng log khổng lồ.

ELK Stack là gì
ELK Stack gồm những thành phần nào?
Để hiểu rõ ELK Stack là gì, chúng ta cần phân tích vai trò của từng mảnh ghép. Hãy tưởng tượng bạn đang xây dựng một nhà máy xử lý dữ liệu, mỗi thành phần của ELK Stack sẽ đóng một vai trò không thể thiếu.

4 Thành Phần Cốt Lõi ELK Stack
1. Elasticsearch
Nếu ELK Stack là một cơ thể, Elasticsearch chính là bộ não và trái tim. Đây là một công cụ tìm kiếm và phân tích (search and analytics engine) phân tán, được xây dựng trên thư viện Apache Lucene.
Vai trò chính của Elasticsearch là lưu trữ toàn bộ dữ liệu log mà Logstash gửi đến và lập chỉ mục (indexing) chúng một cách cực kỳ thông minh.
Nhờ cơ chế lập chỉ mục này, bạn có thể thực hiện các truy vấn tìm kiếm phức tạp trên hàng Terabyte dữ liệu và nhận kết quả gần như ngay lập tức.
- Lưu trữ phân tán: Dữ liệu được lưu dưới dạng tài liệu JSON trên nhiều máy chủ (nodes), giúp tăng khả năng chịu lỗi và mở rộng quy mô dễ dàng.
- API mạnh mẽ: Cung cấp RESTful API cho phép mọi tương tác từ ghi, đọc, xóa, đến truy vấn dữ liệu. Kibana cũng sử dụng chính API này để hiển thị thông tin.
- Tốc độ vượt trội: Khả năng tìm kiếm toàn văn (full-text search) và trả về kết quả trong mili giây là điểm làm nên tên tuổi của Elasticsearch.
Về bản chất, Elasticsearch là một cơ sở dữ liệu NoSQL chuyên dụng cho tìm kiếm. Bạn không chỉ lưu log mà còn có thể lưu bất kỳ loại tài liệu JSON nào khác.
2. Logstash
Logstash hoạt động như một đường ống xử lý dữ liệu (data processing pipeline) mạnh mẽ. Nhiệm vụ của Logstash là nhận dữ liệu từ rất nhiều nguồn khác nhau, biến đổi chúng thành một định dạng thống nhất, sau đó đẩy vào một nơi lưu trữ gọi là “stash” – trong trường hợp này chính là Elasticsearch.
Quy trình hoạt động của Logstash luôn tuân theo 3 bước:
- Input (Đầu vào): Logstash có thể nhận dữ liệu từ vô số nguồn: file log, TCP/UDP socket, Kafka, Redis, Syslog, và nhiều hơn nữa. Bạn chỉ cần cấu hình plugin đầu vào phù hợp.
- Filter (Bộ lọc): Đây là nơi phép màu xảy ra. Tại bước này, bạn có thể “làm sạch” và “làm giàu” dữ liệu. Ví dụ:
- Phân tách log: Dùng bộ lọc
grokđể phân tách một dòng log Nginx thành các trường có cấu trúc (IP, request method, status code, user agent). - Chuyển đổi kiểu dữ liệu: Chuyển đổi một trường từ dạng chuỗi sang số để có thể tính toán.
- Làm giàu dữ liệu: Dùng bộ lọc
geoipđể thêm thông tin vị trí địa lý (thành phố, quốc gia) dựa trên địa chỉ IP.
- Phân tách log: Dùng bộ lọc
- Output (Đầu ra): Sau khi xử lý xong, Logstash sẽ đẩy dữ liệu đến đích. Đích đến phổ biến nhất là Elasticsearch, nhưng cũng có thể là các file, email, hoặc các hệ thống khác.
Nhờ có Logstash, dữ liệu log lộn xộn, không đồng nhất từ nhiều dịch vụ sẽ trở nên có cấu trúc, sạch sẽ và sẵn sàng cho việc phân tích.
3. Kibana
Dữ liệu dù có giá trị đến đâu cũng trở nên vô nghĩa nếu không thể được con người đọc hiểu. Kibana chính là công cụ giải quyết bài toán này. Kibana là một giao diện web, cung cấp khả năng trực quan hóa dữ liệu (data visualization) được lưu trữ trong Elasticsearch.
Với Kibana, bạn có thể:
- Khám phá dữ liệu (Discover): Tìm kiếm, lọc và xem các dòng log thô một cách trực quan, giống như bạn đang dùng bộ lọc trong Excel nhưng ở quy mô lớn hơn hàng triệu lần.
- Tạo biểu đồ (Visualize): Biến những con số khô khan thành các biểu đồ sống động: biểu đồ tròn (pie chart) thể hiện tỷ lệ các mã lỗi HTTP, biểu đồ đường (line chart) theo dõi số lượng request mỗi phút, bản đồ nhiệt (heat map) hiển thị vị trí truy cập…
- Xây dựng Dashboard: Tổng hợp nhiều biểu đồ vào một trang duy nhất gọi là dashboard. Đây là công cụ giám sát toàn diện, giúp đội ngũ kỹ sư có cái nhìn 360 độ về sức khỏe hệ thống trong thời gian thực (real-time data).
Một dashboard Kibana được thiết kế tốt có thể giúp bạn phát hiện sự cố ngay khi chúng vừa chớm nở, thay vì đợi đến khi người dùng phàn nàn.
4. Beats
Ban đầu, việc thu thập log thường do Logstash đảm nhiệm. Tuy nhiên, Logstash khá nặng vì chạy trên máy ảo Java (JVM), việc cài đặt Logstash trên mọi máy chủ trong hệ thống sẽ tiêu tốn nhiều tài nguyên. Để giải quyết vấn đề này, Elastic đã giới thiệu Beats.
Beats là tập hợp các agent thu thập dữ liệu (data shippers) gọn nhẹ, được viết bằng ngôn ngữ Go. Chúng được cài đặt trên các máy chủ client và chỉ làm một nhiệm vụ duy nhất là thu thập và gửi dữ liệu đi.
Có rất nhiều loại Beats cho các mục đích khác nhau:
- Filebeat: Thu thập dữ liệu từ file log. Đây là Beat phổ biến nhất.
- Metricbeat: Thu thập các chỉ số (metrics) của hệ thống (CPU, RAM, Disk, Network) và của các dịch vụ (Nginx, MySQL, Kafka…).
- Packetbeat: “Nghe lén” traffic mạng để thu thập dữ liệu về các giao thức ứng dụng (HTTP, SQL, DNS).
- Winlogbeat: Thu thập dữ liệu Windows Event Logs.
- Auditbeat: Thu thập dữ liệu kiểm toán (audit data) của Linux.
- Heartbeat: Giám sát “sức khỏe” của dịch vụ bằng cách ping hoặc gửi request đến các endpoint.
Beats có thể gửi dữ liệu trực tiếp đến Elasticsearch hoặc gửi qua Logstash để xử lý thêm trước khi lưu trữ.
Kiến trúc và Luồng hoạt động của ELK Stack
Bây giờ bạn đã hiểu vai trò của từng thành phần, hãy cùng xem kiến trúc ELK Stack và luồng hoạt động của chúng kết hợp với nhau như thế nào.
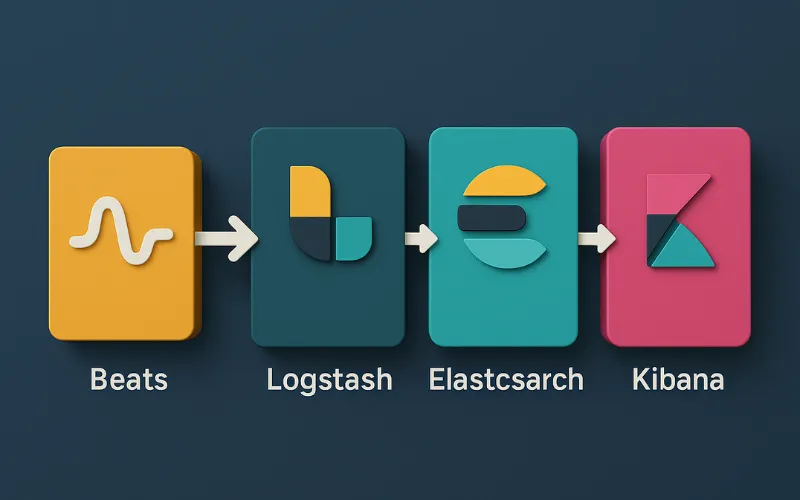
Mô hình phổ biến và cơ bản nhất có luồng dữ liệu như sau:
Beats → Logstash → Elasticsearch → Kibana
Hãy cùng theo dõi hành trình của một dòng log:
- Thu thập: Một người dùng truy cập vào website của bạn. Máy chủ web Nginx ghi lại một dòng log vào file
/var/log/nginx/access.log. Ngay lập tức, Filebeat được cài trên máy chủ đó phát hiện sự thay đổi và đọc dòng log mới. - Gửi và Xử lý: Filebeat gửi dòng log này đến máy chủ Logstash. Logstash nhận dòng log, sử dụng bộ lọc
grokđể bóc tách thông tin như địa chỉ IP, URL truy cập, mã trạng thái (200, 404, 502),… và dùng bộ lọcgeoipđể thêm thông tin quốc gia của IP đó. - Lưu trữ và Lập chỉ mục: Sau khi xử lý xong, Logstash đẩy đối tượng JSON đã có cấu trúc này vào Elasticsearch. Elasticsearch nhận dữ liệu, lập chỉ mục tất cả các trường để chúng sẵn sàng cho việc tìm kiếm.
- Trực quan hóa và Phân tích: Kỹ sư hệ thống mở trình duyệt và truy cập vào Kibana. Kibana gửi một truy vấn đến Elasticsearch: “Hiển thị cho tôi tất cả log có mã trạng thái 5xx trong 15 phút qua”. Elasticsearch trả về kết quả gần như tức thì. Kỹ sư có thể thấy ngay các lỗi đang xảy ra trên dashboard và bắt đầu quá trình điều tra.
Đối với các hệ thống cực lớn, để tăng khả năng chịu tải và chống mất dữ liệu, người ta thường chèn thêm một Message Queue (như Apache Kafka hoặc Redis) vào giữa Beats và Logstash.
Kiến trúc và Luồng hoạt động của ELK Stack
5 lợi ích khi sử dụng ELK Stack
Việc tìm hiểu ELK Stack là gì sẽ trở nên thuyết phục hơn khi bạn thấy được những lợi ích mà bộ công cụ này mang lại.
Mã nguồn mở và Miễn phí
Đây là lợi thế lớn nhất. Bạn có thể bắt đầu sử dụng bộ công cụ cốt lõi của Elastic Stack mà không tốn một đồng chi phí bản quyền nào. Điều này giúp các doanh nghiệp vừa và nhỏ hoặc các startup dễ dàng tiếp cận công nghệ quản lý log chuyên nghiệp, một thứ vốn rất đắt đỏ với các giải pháp thương mại như Splunk.
Cộng đồng lớn và Hệ sinh thái đa dạng
Vì là mã nguồn mở, ELK Stack có một cộng đồng người dùng và nhà phát triển khổng lồ trên toàn thế giới. Hầu hết mọi vấn đề bạn gặp phải đều đã có người hỏi và trả lời trên các diễn đàn. Hệ sinh thái plugin cho Logstash và visualization cho Kibana cũng cực kỳ phong phú.
Khả năng mở rộng linh hoạt (Scalable)
Elasticsearch được thiết kế để chạy dưới dạng cụm (cluster) trên nhiều máy chủ. Khi lượng log của bạn tăng lên, bạn chỉ cần thêm các node mới vào cluster để mở rộng không gian lưu trữ và khả năng xử lý. Việc vận hành một hệ thống lớn cần máy chủ cấu hình mạnh, và đây là lúc các dịch vụ như của thuemaychugiare phát huy tác dụng.
Phân tích và Tìm kiếm gần thời gian thực
Khả năng lập chỉ mục và truy vấn siêu tốc của Elasticsearch cho phép bạn giám sát hệ thống gần như theo thời gian thực. Dữ liệu chỉ mất vài giây từ lúc được tạo ra cho đến khi xuất hiện trên dashboard Kibana.
Không chỉ dành cho Log
Mặc dù khởi đầu với việc quản lý log, Elastic Stack ngày nay đã phát triển thành một nền tảng phân tích dữ liệu toàn diện. Bạn có thể dùng bộ công cụ này để phân tích metrics hệ thống, dữ liệu kinh doanh, theo dõi hành vi người dùng, và nhiều hơn thế nữa.

Tại sao nên sử dụng ELK Stack_ 5 Lợi ích không thể bỏ qua
Ứng dụng của ELK Stack trong thực tế
Lý thuyết sẽ dễ hiểu hơn khi đi kèm với các ứng dụng của ELK Stack trong thực tế.
1. Quản lý và Phân tích Log
Đây là ứng dụng nguyên thủy và phổ biến nhất. Thay vì phải SSH vào 20 máy chủ để tìm lỗi, giờ đây bạn chỉ cần ngồi một chỗ, mở Kibana và tìm kiếm trên toàn bộ log của hệ thống. Bạn có thể nhanh chóng trả lời các câu hỏi như: “User X đã làm những gì?”, “API nào đang bị lỗi nhiều nhất?”, “Tại sao ứng dụng bỗng nhiên chạy chậm?”.
2. Giám sát hiệu năng ứng dụng
Bằng cách sử dụng Elastic APM (một phần của Elastic Stack), các nhà phát triển có thể theo dõi chi tiết hiệu năng của ứng dụng. Họ có thể xem một request mất bao lâu để xử lý, thời gian thực thi các câu lệnh SQL, hoặc phát hiện các “nút thắt cổ chai” trong code.
3. Phân tích bảo mật và SIEM
ELK Stack là một công cụ cực kỳ hữu ích cho các chuyên gia bảo mật. Bằng cách thu thập và phân tích log từ tường lửa, hệ điều hành, ứng dụng…, họ có thể phát hiện sớm các hành vi đáng ngờ, ví dụ như:
- Một địa chỉ IP lạ đang cố gắng đăng nhập thất bại nhiều lần.
- Một user bất thường truy cập vào dữ liệu nhạy cảm ngoài giờ làm việc.
- Phát hiện các mẫu tấn công đã biết (known attack patterns).
4. Business Intelligence
Doanh nghiệp có thể đẩy dữ liệu về hành vi người dùng (click chuột, xem sản phẩm, thêm vào giỏ hàng) vào ELK Stack. Từ đó, đội ngũ marketing và sản phẩm có thể xây dựng các dashboard để phân tích:
- Sản phẩm nào đang được xem nhiều nhất?
- Người dùng từ quốc gia nào mua hàng nhiều nhất?
- Tỷ lệ chuyển đổi của một chiến dịch quảng cáo là bao nhiêu?
Hướng dẫn cài đặt ELK Stack cơ bản với Docker
Cách nhanh nhất để trải nghiệm ELK Stack là gì là sử dụng Docker. Dưới đây là hướng dẫn cài đặt cơ bản.
- Yêu cầu: Máy tính của bạn đã cài đặt Docker và Docker Compose.
- Tạo file
docker-compose.yml:Tạo một file với têndocker-compose.ymlvà dán nội dung sau vào:version: '3.7' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0 container_name: elasticsearch environment: - discovery.type=single-node - xpack.security.enabled=false ports: - "9200:9200" networks: - elk kibana: image: docker.elastic.co/kibana/kibana:8.9.0 container_name: kibana ports: - "5601:5601" depends_on: - elasticsearch networks: - elk networks: elk: driver: bridgeLưu ý: Phiên bản
8.9.0là ví dụ, bạn có thể thay bằng phiên bản mới hơn. - Khởi chạy:Mở terminal trong thư mục chứa file trên và chạy lệnh:
docker-compose up -d - Truy cập:
- Chờ vài phút để các container khởi động xong.
- Truy cập Kibana qua trình duyệt: http://localhost:5601.
- Kiểm tra Elasticsearch: http://localhost:9200.
Đây là một thiết lập rất cơ bản. Một hệ thống thực tế sẽ cần cấu hình Logstash, Filebeat và nhiều tùy chỉnh bảo mật, hiệu năng khác.
Câu hỏi thường gặp về ELK Stack (FAQ)
Dưới đây là một số câu hỏi mà thuemaychugiare thường nhận được từ khách hàng khi họ tìm hiểu về giải pháp này.
ELK Stack có miễn phí không?
Có. Các thành phần cốt lõi của Elastic Stack (Elasticsearch, Kibana, Beats, Logstash) được phát hành dưới giấy phép mã nguồn mở và miễn phí sử dụng (Bản quyền Basic). Tuy nhiên, Elastic cũng cung cấp các gói trả phí (Gold, Platinum, Enterprise) với các tính năng nâng cao như machine learning, alerting, bảo mật chi tiết, và hỗ trợ kỹ thuật chuyên nghiệp.
Sự khác biệt giữa ELK Stack và Elastic Stack là gì?
Về cơ bản chúng là một. Elastic Stack là tên gọi chính thức và hiện đại hơn, phản ánh đúng hơn sự phát triển của bộ công cụ khi có thêm sự góp mặt của Beats. Khi ai đó nói về ELK Stack trong bối cảnh hiện nay, họ thường cũng đang ngụ ý đến cả Beats.
So sánh ELK Stack với Splunk và Graylog?
Đây là ba giải pháp quản lý log hàng đầu, nhưng có những khác biệt lớn:
- Chi phí: ELK Stack có phiên bản mã nguồn mở miễn phí, trong khi Splunk chủ yếu là giải pháp thương mại với chi phí khá cao, tính theo lượng dữ liệu mỗi ngày. Graylog cũng có phiên bản mã nguồn mở nhưng các tính năng doanh nghiệp cũng yêu cầu trả phí.
- Linh hoạt: ELK Stack được đánh giá là cực kỳ linh hoạt. Bạn có toàn quyền kiểm soát, tùy chỉnh và tích hợp với các hệ thống khác. Splunk và Graylog có xu hướng “đóng gói” và dễ sử dụng hơn cho người mới bắt đầu nhưng kém linh hoạt hơn.
- Cộng đồng: Do tính chất mã nguồn mở, cộng đồng của ELK Stack rất lớn, giúp việc tìm kiếm tài liệu và hỗ trợ dễ dàng hơn.
Lời kết
Việc hiểu rõ ELK Stack là gì không chỉ là nắm bắt định nghĩa của một bộ công cụ. Đây là việc trang bị cho mình một tư duy và một giải pháp mạnh mẽ để biến những dữ liệu log tưởng chừng vô tri thành những thông tin chi tiết, có giá trị, giúp hệ thống vận hành ổn định, an toàn và hiệu quả hơn. Từ việc gỡ lỗi nhanh chóng đến phân tích kinh doanh, Elastic Stack đã chứng tỏ vai trò không thể thiếu trong thế giới công nghệ hiện đại.
Để triển khai một hệ thống ELK Stack ổn định, đặc biệt với lượng dữ liệu lớn, bạn sẽ cần một hạ tầng máy chủ đủ mạnh mẽ và đáng tin cậy. Nếu có bất kỳ nhu cầu nào về máy chủ cấu hình cao, đừng ngần ngại liên hệ với thuemaychugiare để được tư vấn giải pháp phù hợp nhất.
Để lại một bình luận